

Cette page a été traduite automatiquement et pourrait contenir des erreurs
Cette page a été traduite automatiquement et pourrait contenir des erreurs
Découvrez la version 2.26 de DHIS2, qui comprend de nombreuses nouvelles fonctionnalités, applications, améliorations et corrections de bugs. Sur cette page, vous pouvez trouver des informations sur cette version du logiciel, y compris des descriptions de fonctionnalités, des liens vers la documentation technique et plus encore.
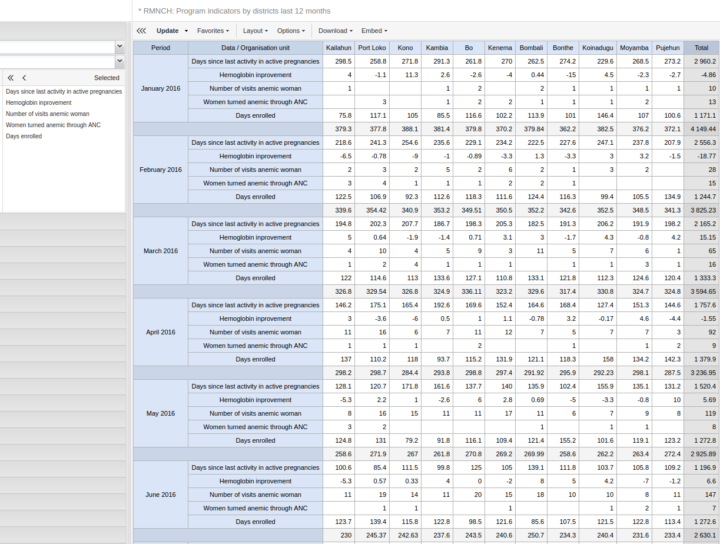
Les indicateurs de programme peuvent désormais utiliser un nouvel aspect du moteur d’analyse pour les inscriptions aux programmes. Cela signifie que vous pouvez comparer des données d’événements et de dates provenant de différents stades et événements d’une affiliation. Cela permet de calculer des indicateurs tels que « le nombre moyen de jours d’hospitalisation » et « l’amélioration du taux d’hémoglobine depuis la première visite ».
[ Démonstration ] [ Capture d’écran ][Documentation ]
Vous pouvez désormais envoyer à vos utilisateurs, par courrier électronique, des analyses de données sous forme de rapports, de graphiques et de cartes. Cela permet d’améliorer la connaissance et la visibilité de vos données et peut encourager les gens à examiner plus activement l’analyse. L’analyse push est basée sur des tableaux de bord et peut être configurée, exécutée et programmée à partir de l’application Maintenance. Vous pouvez également l’exécuter immédiatement et le prévisualiser à partir du menu contextuel.
[ Capture d’écran][Démo 1 | 2 ]
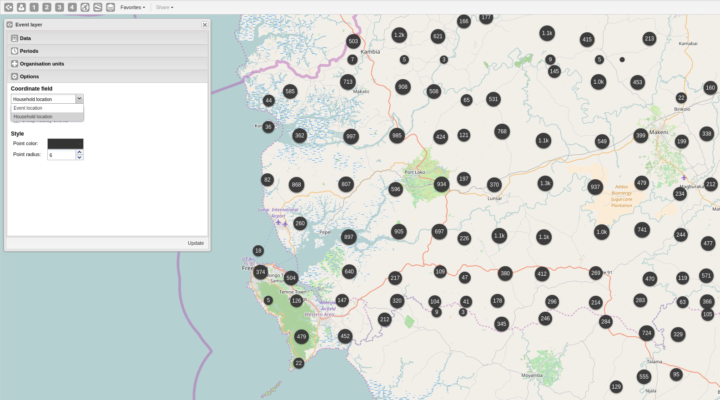
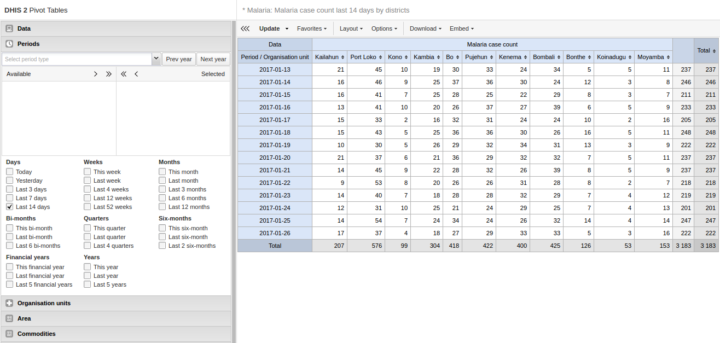
En utilisant la couche d’événements dans l’application SIG, vous pouvez maintenant spécifier l’élément de données ou l’attribut à utiliser comme base pour l’analyse des événements et le regroupement. L’élément de données doit être de type coordonné. Par exemple, pour un programme de lutte contre le paludisme, vous pouvez avoir des éléments de données de type coordonnées pour le lieu d’infection et l’emplacement du ménage, et visualiser ces emplacements sur la carte pour les cas de paludisme.
[ Capture d’écran][Docs ]
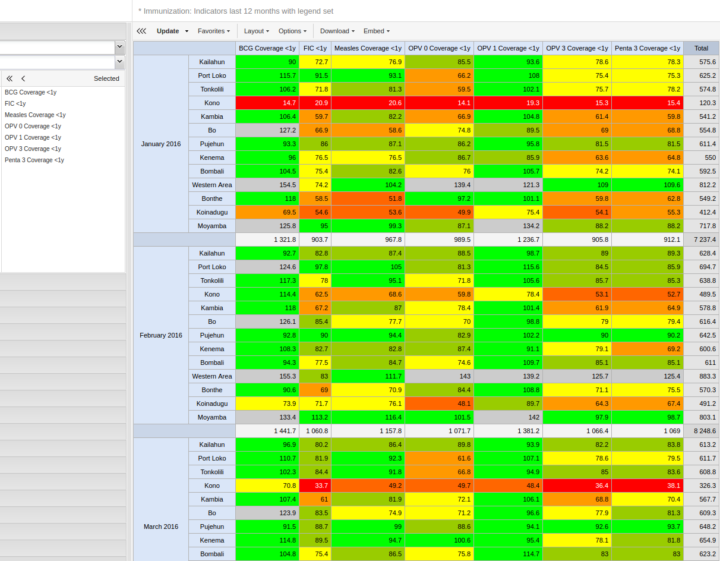
Vous pouvez désormais spécifier si le texte ou l’arrière-plan des cellules des tableaux croisés dynamiques doit être coloré en fonction des ensembles de légendes. Cela permet par exemple de créer des cartes de pointage, où les valeurs élevées et faibles peuvent être facilement identifiées. Allez dans Tableau croisé dynamique > Options > Style d’affichage de la légende.
[ Capture d’écran][Docs ]
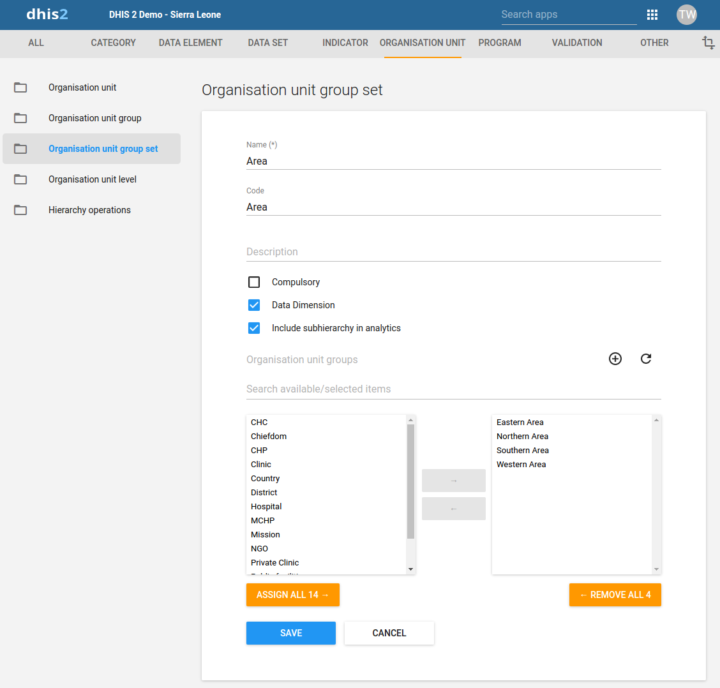
Les ensembles d’unités d’organisation disposent d’une nouvelle option permettant d’inclure la sous-hiérarchie des unités d’organisation dans les groupes lors de l’agrégation des données dans les apps d’analyse. Cela peut simplifier la gestion des unités d’organisation lorsqu’il y a de nombreuses unités d’organisation au bas de la hiérarchie qui devraient toutes appartenir à une unité d’organisation plus haut dans la hiérarchie. Par exemple, vous pouvez créer des hiérarchies supplémentaires en regroupant tous les établissements de plusieurs districts dans un groupe, puis en affectant les nouveaux groupes à un ensemble de groupes d’unités d’organisation.
[ Capture d’écran 1 | 2 ][Docs ]
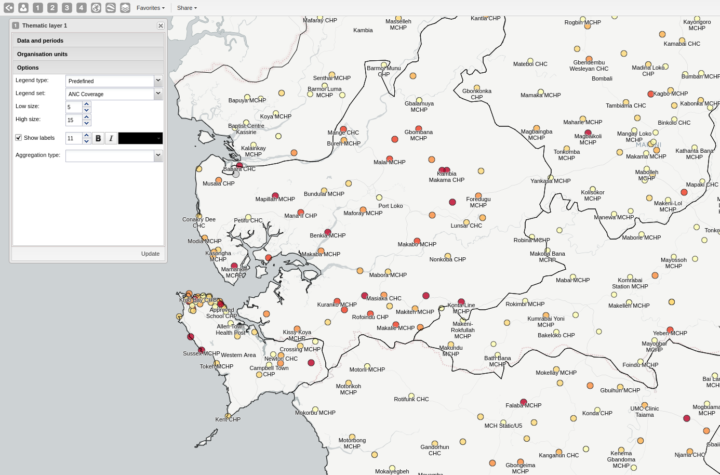
Les étiquettes sont positionnées plus intelligemment sur la carte afin d’éviter les collisions. L’interactivité de la couche limite est désactivée lorsqu’elle est combinée avec une couche thématique. Les échelles de couleur automatiques des cartes thématiques peuvent être inversées (c’est-à-dire de bas en haut ou de haut en bas).
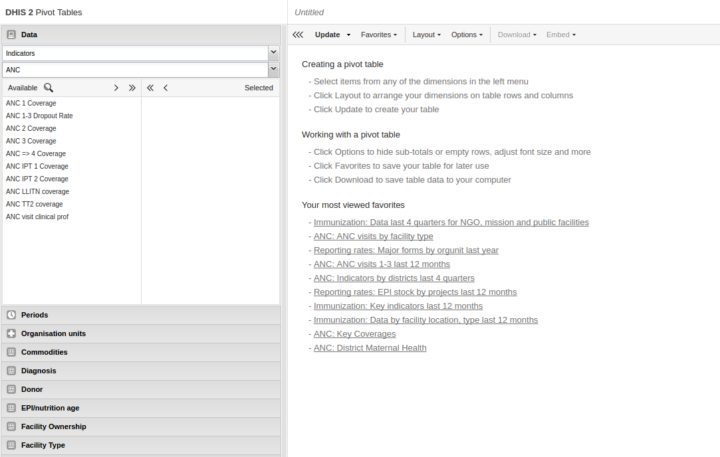
L’écran d’ouverture des applications de tableau croisé dynamique affiche désormais un lien vers les 10 favoris les plus consultés par l’utilisateur actuel. Cela vous permet d’accéder rapidement aux données les plus pertinentes.
[ Capture d’écran ]
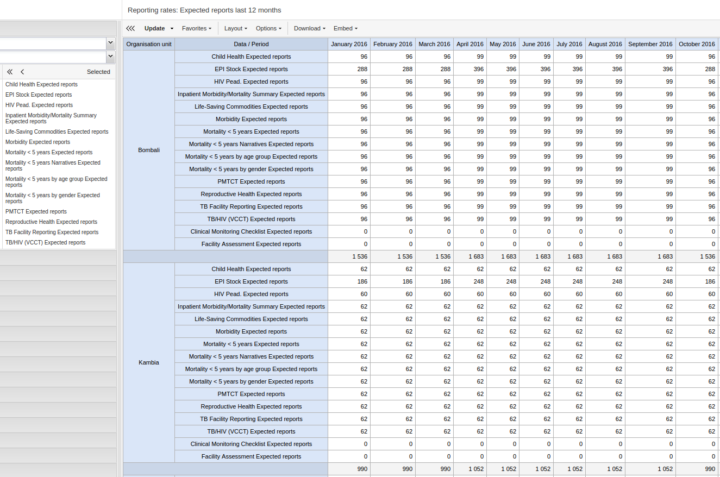
Dans les analyses de taux de rapport dans les pivots et les graphiques, le nombre de rapports attendus est toujours affiché, même s’il n’existe pas d’enregistrements d’exhaustivité.
[ Capture d’écran ]
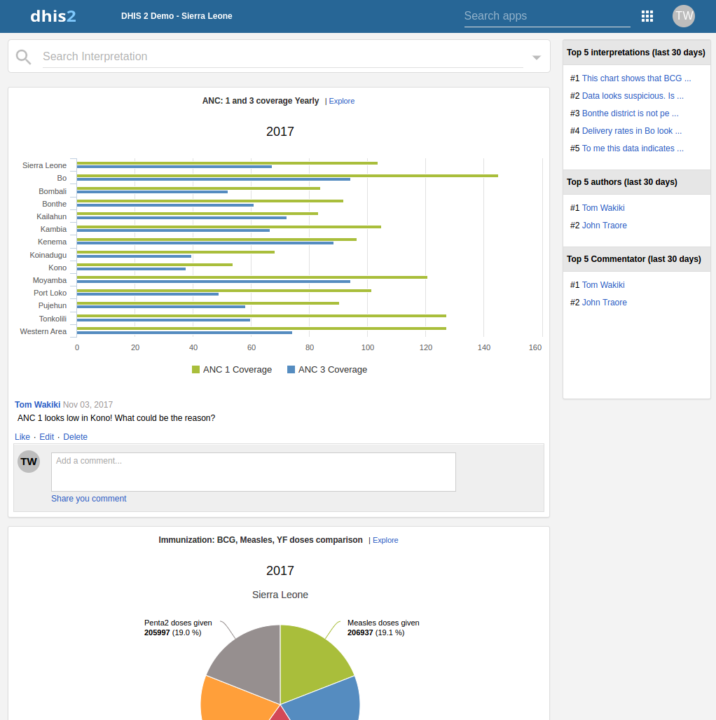
L’application Interprétations a été réécrite et prend désormais en charge les rapports et les graphiques d’événements, en utilisant les plugins de visualisation dynamique, et offre une meilleure solution de commentaires.
[ Capture d’écran ]
La génération de tables analytiques et les performances des requêtes analytiques ont été considérablement améliorées. Selon la configuration du système, l’amélioration est de l’ordre de 20 à 40 %.
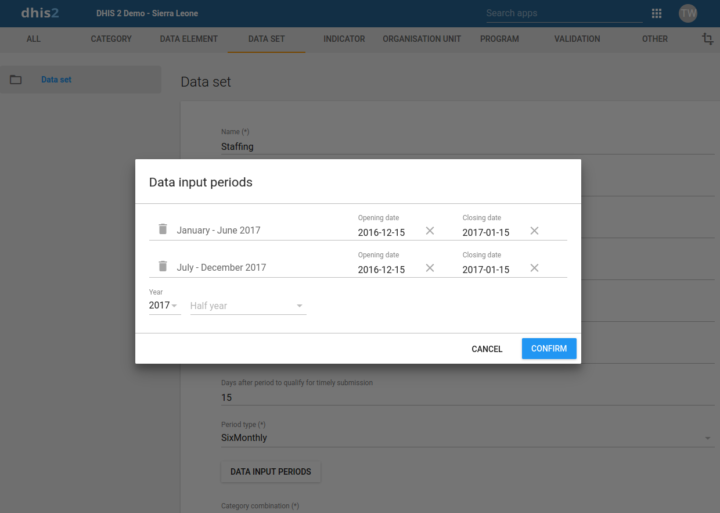
Vous pouvez désormais spécifier exactement quelles périodes doivent être ouvertes à la saisie des données par ensemble de données. Vous pouvez également déterminer quand ces périodes seront disponibles pour la saisie des données. Ceci est utile lorsque vous avez besoin d’un contrôle plus fin sur les périodes pour lesquelles il devrait être possible de saisir des données, et lorsque vous devez programmer ces périodes pour qu’elles s’ouvrent à des moments précis.
[ Capture d’écran] [ Documentation]
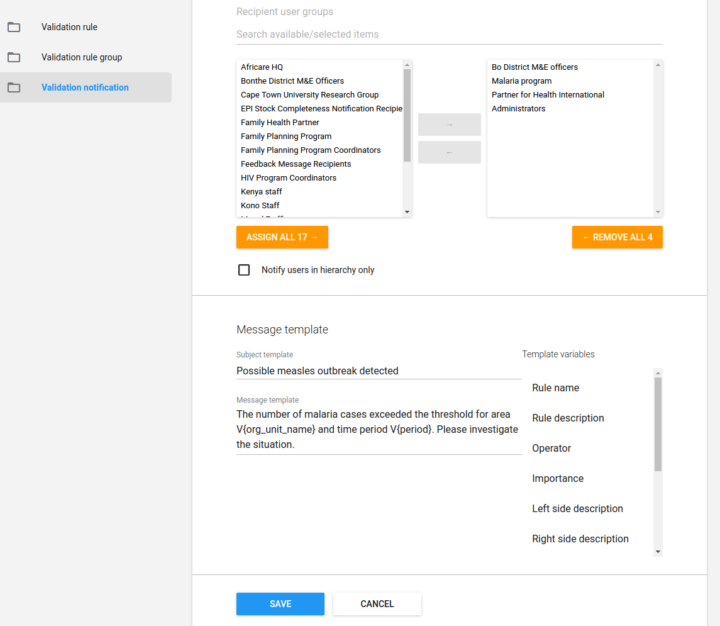
Vous pouvez désormais spécifier des modèles pour les notifications à envoyer en cas de violation de la validation des données. Les modèles vous permettent de contrôler entièrement le texte de la notification et prennent en charge des variables pour injecter le nom de l’unité organisationnelle, la période, la règle de validation et la date du jour.
[ Démonstration ] [ Capture d’écran ] [ Documentation ]
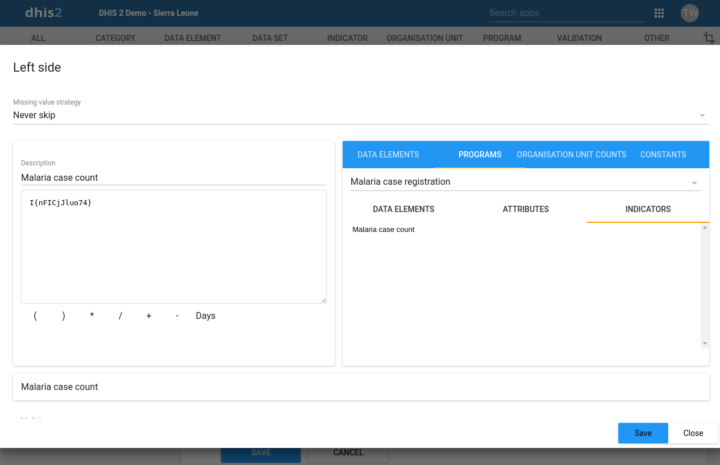
Vous pouvez désormais utiliser des éléments de données de programme, des attributs d’entités suivies et des indicateurs de programme dans les règles de validation. Les valeurs agrégées seront utilisées à partir du moteur d’analyse des événements lorsque les expressions des règles de validation sont évaluées. Cela permet de combiner des données de routine et des données d’événements dans la même règle de validation. Ceci est utile pour comparer les seuils collectés en tant que données de routine avec les cas de maladie déclarés en tant qu’événements, par exemple. La gestion des règles de validation est désormais disponible dans l’app Maintenance.
[ Démonstration ] [ Capture d’écran ] [ Documentation ]
Nous avons inclus une nouvelle application pour la traduction en masse du contenu des bases de données. Vous pouvez traduire beaucoup plus rapidement un grand nombre de métadonnées en sélectionnant le type d’objet, puis en traduisant tous les objets à partir d’une liste. Ouvrez-la à partir de Apps > Translations.
[ Démonstration ] [ Capture d’écran ]
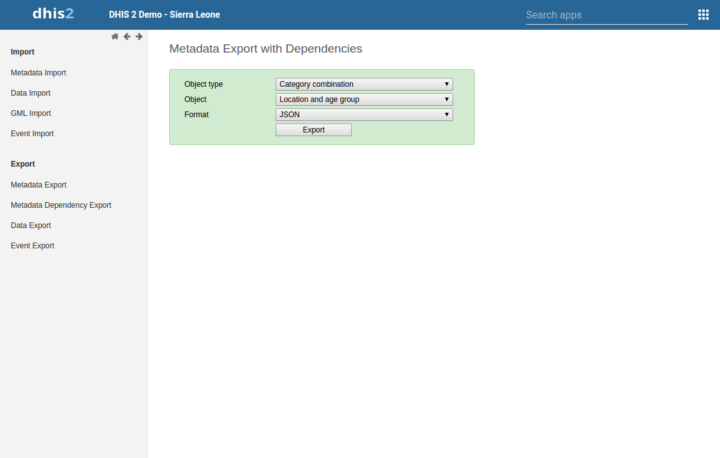
L’exportation de métadonnées avec dépendances prend désormais en charge l’exportation de combinaisons de catégories, qui incluront tous les objets de catégorie connexes. Ceci est utile lors de l’échange de métadonnées entre les instances.
[ Démonstration ] [ Capture d’écran ]
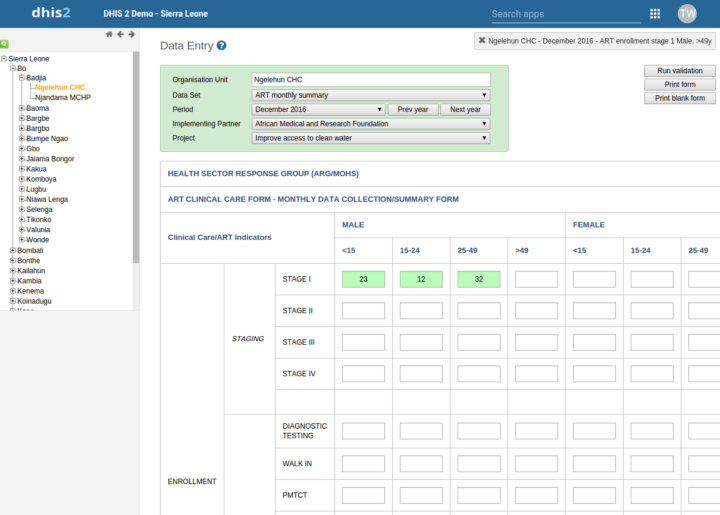
Dans l’application Saisie des données, lorsque les sélections d’ensembles de données ou de catégories ne comportent qu’une seule option, celle-ci est automatiquement sélectionnée. La saisie des données est ainsi plus efficace.
[ Capture d’écran ]
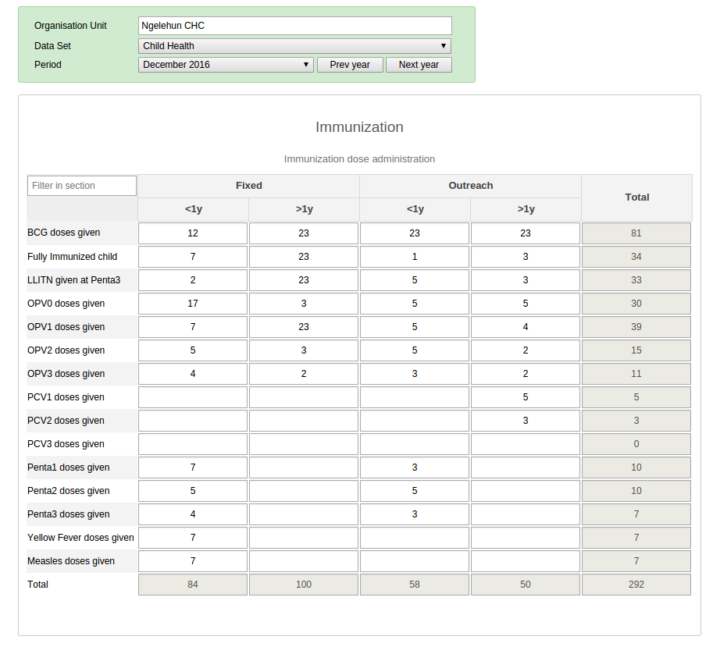
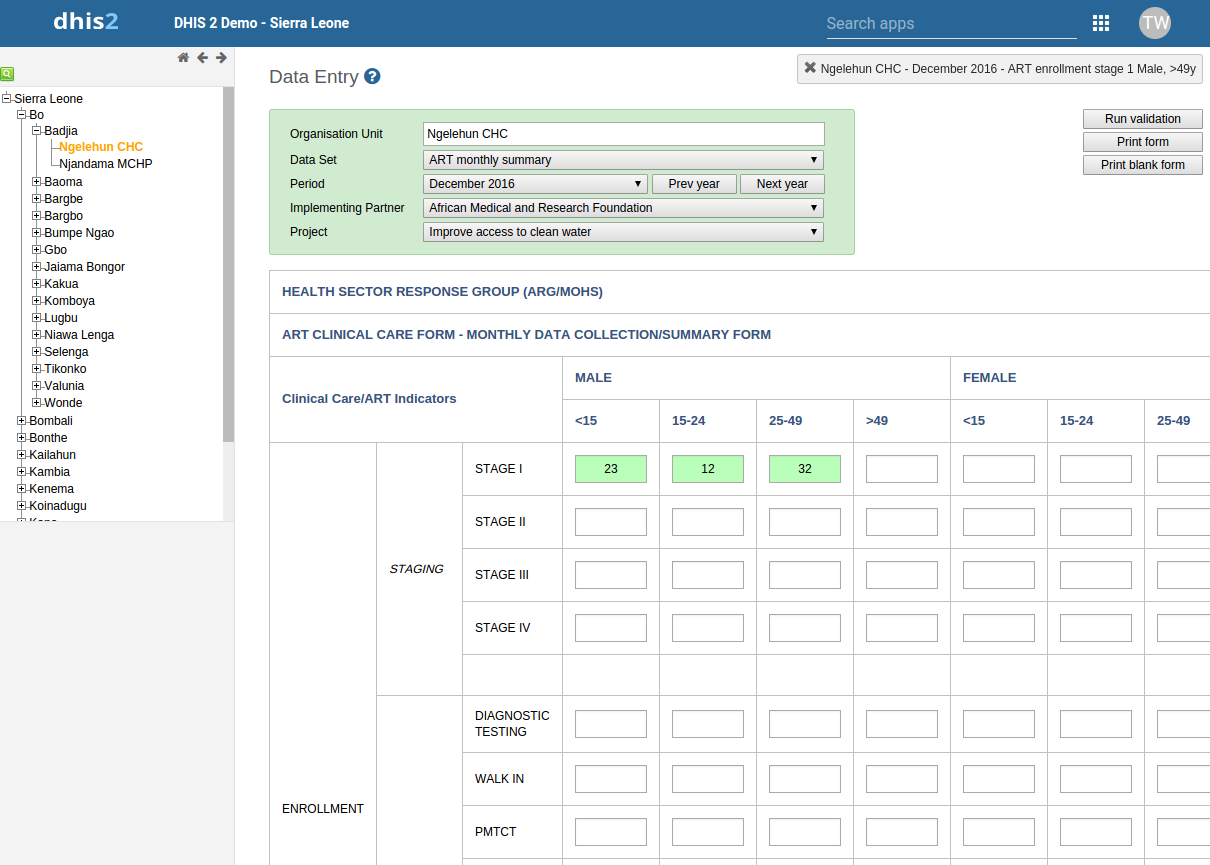
Les formulaires de section peuvent être configurés pour afficher les totaux des colonnes et des lignes dans la saisie des données agrégées. Configurez-le à partir des sections Maintenance > Ensembles de données >. Consultez l’ensemble de données « santé reproductive » sur la démo.
[ Démonstration ] [ Capture d’écran ] [ Documentation ]
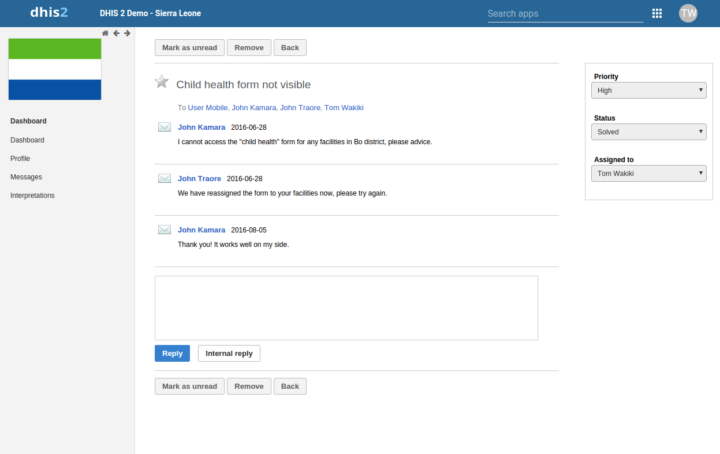
Dans l’application Messagerie, un message peut désormais être attribué à un utilisateur DHIS2. Cela vous permet de traiter les messages comme des tickets d’assistance et de les attribuer à des utilisateurs (agents). Notez que cette fonction n’est disponible que pour les utilisateurs appartenant au groupe d’utilisateurs « destinataires du feedback ».
[ Démonstration ] [ Capture d’écran ] [ Documentation ]
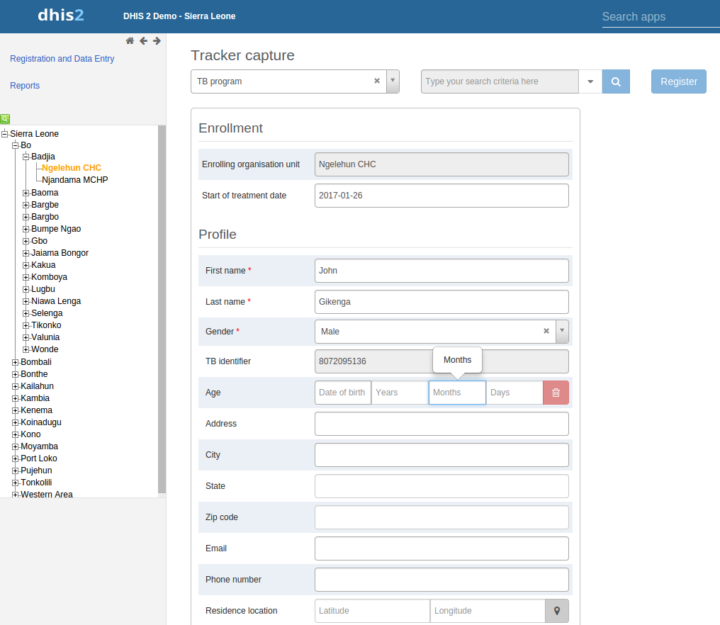
Les éléments de données et les attributs prennent en charge un nouveau type de valeur : « Age ». Cela se présente sous la forme d’un widget dans les applications Saisie Tracker et signifie que vous devez saisir l’âge en semaines, en mois ou en années. L’entrée sélectionnée est convertie en date de naissance. Cela simplifie la saisie de l’âge aux points de soins, par exemple.
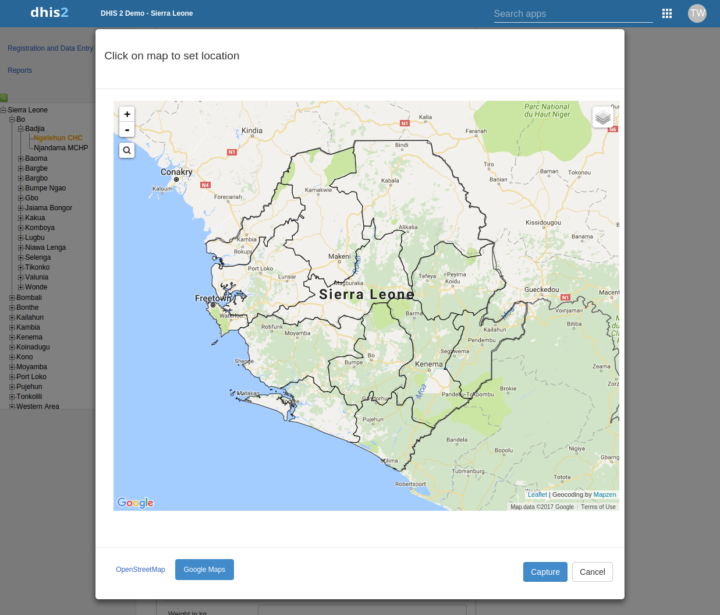
Lors de la capture de coordonnées dans Event Capture et Tracker Capture, vous pouvez désormais basculer entre l’utilisation de Google Maps et OpenStreetMap comme carte de base.
[ Capture d’écran ]
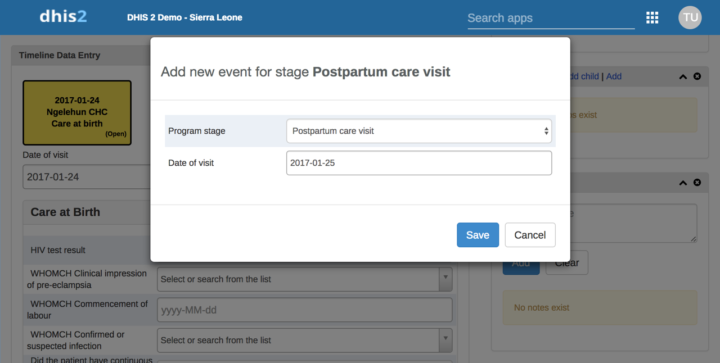
Les règles de programme prévoient désormais une action pour masquer les étapes du programme. Ceci est utile pour les enquêtes sur les cas de maladie, par exemple, lorsque les différents stades ne sont pertinents que pour certaines maladies.
[ Capture d’écran ]
Nous avons ajouté un nouveau paramètre système pour la mise en cache des données d’analyse, qui permet de mettre en cache les données datant de plus d’un certain nombre d’années. Vous pouvez éviter de mettre en cache vos données les plus récentes, tandis que les données plus anciennes qui ne changent jamais peuvent être mises en cache.
[ Documentation ]
Un nouveau paramètre système permet de contrôler si les données analytiques mises en cache doivent être publiques ou privées, c’est-à-dire si les proxys doivent pouvoir mettre le contenu en cache. Cela permet de renforcer la sécurité des données sensibles tout en permettant aux navigateurs web de mettre du contenu en cache.
[ Documentation ]
Nous avons ajouté un paramètre système qui définit à partir de combien d’années l’approbation doit être pertinente. Après le nombre d’années spécifié, toutes les données deviennent disponibles pour l’analyse, même si elles n’ont pas été approuvées. Cela signifie que les données seront automatiquement approuvées et visibles après un certain nombre d’années. Cela vous permet d’élaguer la table d’approbation et de vous assurer que les performances du système ne se dégradent pas.
[ Documentation ]
Les variables d’environnement sont désormais prises en charge dans le fichier de configuration dhis.conf. Vous pouvez l’utiliser par exemple pour externaliser les informations de connexion à la base de données telles que les URL, l’utilisateur et le mot de passe, au lieu de stocker ces données directement dans le fichier de configuration. Cette fonction est utile pour l’administration des serveurs et pour les environnements en nuage.
[ Documentation ]
Le système permet désormais de verrouiller le compte de l’utilisateur pendant 15 minutes après cinq tentatives de connexion infructueuses. Cela permet d’éviter les attaques d’authentification par force brute.
[ Documentation ]
Le délai d’attente de la session peut maintenant être configuré à partir du fichier de configuration dhis.conf. Cela permet de se conformer à des règles de sécurité spécifiques.
[ Documentation ]
Nous avons introduit une nouvelle ressource pour récupérer les données analytiques sans agrégation à /api/analytics/rawData. Cette ressource vous permet de récupérer des données brutes dénormalisées à travers n’importe quelle dimension de données. Ceci est utile lors de l’intégration d’outils de BI/analyse tiers, car vous obtiendrez des valeurs de données avec toutes les dimensions de données « aplaties » sans aucune pré-agrégation, permettant à l’outil externe d’effectuer l’agrégation et le filtrage.
[ Documentation ]
L’API analytique vous permet de spécifier les critères de mesure à appliquer avant l’agrégation des données. Cela permet de mieux filtrer les données avant de les agréger.
[ Documentation ]
Vous pouvez désormais utiliser la syntaxe de filtrage des champs connue de l’API des métadonnées sur les vues SQL. Cela vous permet de récupérer uniquement les champs (colonnes) qui vous intéressent dans des vues SQL volumineuses.
[ Démonstration ][ Documentation ]
Les éléments de données avec les données correspondantes et les valeurs d’audit peuvent être élagués à l’aide de la ressource /api/maintenance/dataPruning.
[ Documentation ]
La ressource API pour l’importation et l’exportation des enregistrements relatifs à l’exhaustivité de l’ensemble des données a été réécrite. Elle est désormais beaucoup plus évolutive et prend en charge davantage de fonctionnalités permettant de contrôler ce qui doit être échangé.
[ Documentation ]
Les événements sont désormais supprimés « en douceur », c’est-à-dire qu’ils sont marqués comme supprimés au lieu d’être supprimés dans la base de données. La ressource événements peut inclure des événements supprimés dans la réponse, ce qui permet aux clients de traiter les événements qui ont été supprimés sur le serveur.
[ Démonstration ] [ Documentation ]
Cliquez sur les liens du tableau ci-dessous pour plus d’informations sur cette version du logiciel.
| To find more details about... | Follow this link: |
|---|---|
| Download release and sample database | Downloads |
| Documentation | Documentation |
| Upgrade notes | Upgrade |
| Source code on Github | DHIS2 source code |
| DHIS2 community | DHIS2 Community of Practice |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Capture d’écran]](https://s3-eu-west-1.amazonaws.com/content.dhis2.org/releases/screenshots/26/gis-positioning.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}