DHIS2 Composant Camel
Un wrapper Apache Camel pour la bibliothèque client DHIS2 qui permet aux utilisateurs de l’utiliser dans les routes Camel (où les flux de travail d’intégration sont définis).

DHIS2 soutient l’utilisation de HL7 FHIR dans les mises-en-œvre dans le domaine de la santé. Les métadonnées des systèmes DHIS2 peuvent être mises en correspondance avec les profils FHIR standard, ce qui assure la compatibilité avec les profils de patients FHIR nationaux et les lignes directrices SMART de l’OMS. Sur cette page, vous pouvez en savoir plus sur les outils et les approches pour l’échange et l’intégration de données DHIS2 à l’aide de FHIR.
HL7Ⓡ FHIRⓇ (Fast Healthcare Interoperability Resources) est une norme dont la conservation est assurée par Health Level Seven International. Extrait de la description du produit HL7 FHIR :
FHIR est une norme d’interopérabilité destinée à faciliter l’échange d’informations sur les soins de santé entre les prestataires de soins, les patients, les soignants, les payeurs, les chercheurs et toute autre personne impliquée dans l’écosystème des soins de santé. Il se compose de deux parties principales : un modèle de contenu sous la forme de « ressources » et une spécification pour l’échange de ces ressources sous la forme d’interfaces RESTful en temps réel ainsi que de messages et de documents.
Alors que les normes précédentes comme HL7 v2 n’ont pas disparu, FHIR adopte une approche moderne, par exemple en utilisant les paradigmes RESTful qui sont plus familiers aux développeurs d’applications web modernes. L’intérêt et l’adoption de FHIR se sont accrus au cours des dernières années, les principaux fournisseurs tels que Microsoft, Google, Epic et d’autres ayant créé des outils et des interfaces compatibles avec FHIR. La communauté internationale du développement, y compris la communauté OpenHIE et les groupes de travail techniques de l’OMS, a également fait preuve d’un intérêt et d’un travail considérables.
FHIR définit une riche ontologie de ressources de base telles que Patient, Observation, ValueSet, CodeSystem, etc. L’évolution rapide de FHIR a entraîné la nécessité d’établir différents niveaux de maturité pour différentes ressources. Ainsi, bien qu’il soit en développement constant, il existe un nombre croissant de ressources qui ont acquis un statut normatif.
Les ressources de base sont définies dans un souci d’extensibilité et de paramétrage. Les champs et les codes requis pour décrire un patient aux États-Unis, par exemple, peuvent être très différents de ceux requis en Norvège ou en Sierra Leone. Le processus de paramétrage, d’extension et de limitation des ressources de base est connu sous le nom de profilage. L’établissement d’un consensus autour des profils est une activité clé pour établir l’interopérabilité réelle entre les systèmes participants. En termes de DHIS2, cela est similaire aux instances d’entités suivies (TEI) – le fait que deux systèmes DHIS2 supportent les TEI n’implique pas nécessairement qu’ils puissent échanger des données sans harmoniser les attributs, les ensembles d’options, etc.
Les ressources FHIR de base sont gérées par le groupe de gestion HL7 FHIR, mais toute organisation peut créer et publier des profils. Ainsi, par exemple, il est courant que les juridictions nationales créent des profils nationaux. Il y a eu quelques tentatives d’harmonisation de ces activités par le biais d’initiatives telles que l’International Patient Summary.
Un concept connexe au profil FHIR est le guide de mise-en-œvre (IG) FHIR. Les IG fournissent un moyen cohérent de décrire des collections connexes de ressources FHIR profilées pour répondre à des domaines de problèmes particuliers. Ils intègrent généralement des artefacts lisibles par machine ainsi que des textes narratifs, des exemples, etc.
Le DHIS2, comme presque tous les grands systèmes logiciels de santé numérique établis, est construit autour d’un modèle de données qui a évolué pendant de nombreuses années pour répondre efficacement à un large éventail de cas d’utilisation dans le domaine de la santé et au-delà. Le modèle est stable, robuste et bien documenté. Nous considérons FHIR comme une norme d’interopérabilité, plutôt que comme un remplacement de notre modèle interne. Le défi consiste donc à créer des correspondances efficaces entre les ressources du modèle DHIS2 et les ressources équivalentes ou similaires du modèle FHIR. Ce défi n’est pas trivial, car les deux modèles sont hautement personnalisables et extensibles. C’est pourquoi nous abordons le problème de manière progressive et itérative, en préférant ancrer notre approche dans des applications concrètes.
Techniquement, cela implique l’utilisation de transformations, d’interfaces et de façades, qui traduisent les ressources FHIR sur le modèle de données DHIS2 sous-jacent à l’aide d’un cadre d’intégration tel qu’Apache Camel (par exemple, la transformation d’une Tracked Entity Instance (TEI) en un profil de patient FHIR). Ce point est décrit plus en détail dans la section sur la technologie ci-dessous.
Cette approche a déjà été utilisée avec succès dans le monde réel. Par exemple, dans le cadre de notre travail avec la mise en œuvre régionale de la sécurité des vaccins (ESAVI) de l’OPS, qui utilise une version paramétrée de la collection de métadonnées AEFI Tracker du DHIS2 pour collecter des données qui sont mappées sur un questionnaire profilé FHIR pour faciliter le partage des données avec d’autres systèmes, et qui peut par la suite soutenir la compatibilité avec la base de données mondiale de pharmacovigilance Vigibase. Il s’agit d’un bon exemple de processus d’interopérabilité fondé sur les besoins réels d’un pays ou d’un contexte régional spécifique, par opposition aux projets fondés sur des schémas abstraits, qui tendent à être plus difficiles et à avoir moins d’impact.
Dans tous les cas que nous avons explorés jusqu’à présent, nous avons pu transformer avec succès les données DHIS2 en FHIR. L’équipe d’intégration du DHIS2 continue de travailler avec des partenaires locaux et internationaux sur les besoins spécifiques de FHIR et le développement d’approches génériques qui peuvent être partagées et adaptées. Si vous avez un problème à résoudre avec FHIR, contactez-nous : integration@dhis2.org
Mapping to Questionnaire / QuestionnaireResponse : Les questionnaires FHIR constituent un mécanisme pratique d’interopérabilité entre des systèmes qui ne partagent pas nécessairement la même riche collection de ressources FHIR spécifiques à un domaine. Les référentiels FHIR natifs peuvent mettre en correspondance des questionnaires en utilisant, par exemple, la SDC (saisie des données structurées). De même, du côté du DHIS2, nous pouvons faire correspondre les formulaires de saisie des données Tracker et agrégées aux questionnaires. Le questionnaire fait abstraction de la différence de modèle de données entre les deux parties.
Comme nous l’avons vu plus haut, cette approche a été utilisée efficacement par l’OPS pour l’échange de données sur les trackers. Nous travaillons également actuellement sur une correspondance standardisée entre les ensembles de données agrégées du DHIS2 et les questionnaires FHIR.
Mapping to Patient Resource : Un profil FHIR spécifique sur lequel nous nous sommes concentrés est l’International Patient Standard (IPS). L’équipe DHIS2 a traduit les métadonnées du Tracker DHIS2 en une charge utile Patient conforme à l’IPS. Cela nous permettra à terme de prendre en charge l’importation et l’exportation des données démographiques des patients (par exemple dans le cadre de l’orientation des patients sous la forme d’un résumé international du patient).
Exposition des métadonnées DHIS2 en tant que ressources FHIR : Nous avons développé des transformations pour exprimer les ensembles d’options DHIS2 et les unités d’organisation en tant que ValueSets FHIR et ressources compatibles mCSD. En généralisant cette expérience, nous travaillons à ce que les mises-en-œvres puissent exposer et décrire leurs métadonnées structurelles de manière plus générale à l’aide de FHIR.
En utilisant les outils que nous avons développés jusqu’à présent, il est possible de prendre certains aspects des métadonnées de DHIS2 et de produire un guide de mise-en-œvre FHIR à partir de celles-ci. Cela signifie que les pays et les organisations qui utilisent DHIS2 comme environnement auteur national (pour collecter des données sur les patients, agréger des rapports, etc.) – ce qui est un rôle typique pour DHIS2 au sein de l’architecture d’information numérique sur la santé d’un pays – peuvent générer des profils FHIR qui représentent les informations qui se trouvent dans leur instance DHIS2.
L’équipe d’intégration de DHIS2 utilise le middleware open-source Apache Camel pour divers projets d’intégration. Pour faciliter la vie des ingénieurs d’intégration, nous avons développé une bibliothèque client DHIS2 java et un composant DHIS2 Camel, qui facilite la création de routes entre les points d’extrémité DHIS2 et d’autres composants Camel (tels que FHIR, HL7v2x, etc.). Nous l’avons trouvé particulièrement utile pour prendre en charge les formats de données et les transformations FHIR. Il existe d’autres options d’intergiciels, mais nous avons choisi Apache Camel en raison de sa flexibilité, de sa maturité et de son utilisation extensive dans une variété d’industries, ce qui signifie qu’il existe déjà de nombreux connecteurs qui peuvent aider à relier DHIS2 à n’importe quel système avec lequel les pays veulent l’intégrer. Il existe plusieurs exemples d’utilisations similaires de Camel pour la transformation des données de santé, notamment l’outil ETL OpenMRS, le pont OpenEHR FHIR et la plateforme d’intégration Open eHealth.
Cette approche consiste à communiquer avec l’instance DHIS2 d’un côté du connecteur Apache Camel, puis à effectuer une transformation qui traduit les données DHIS2 en format FHIR. Il existe deux méthodes pour ce faire :
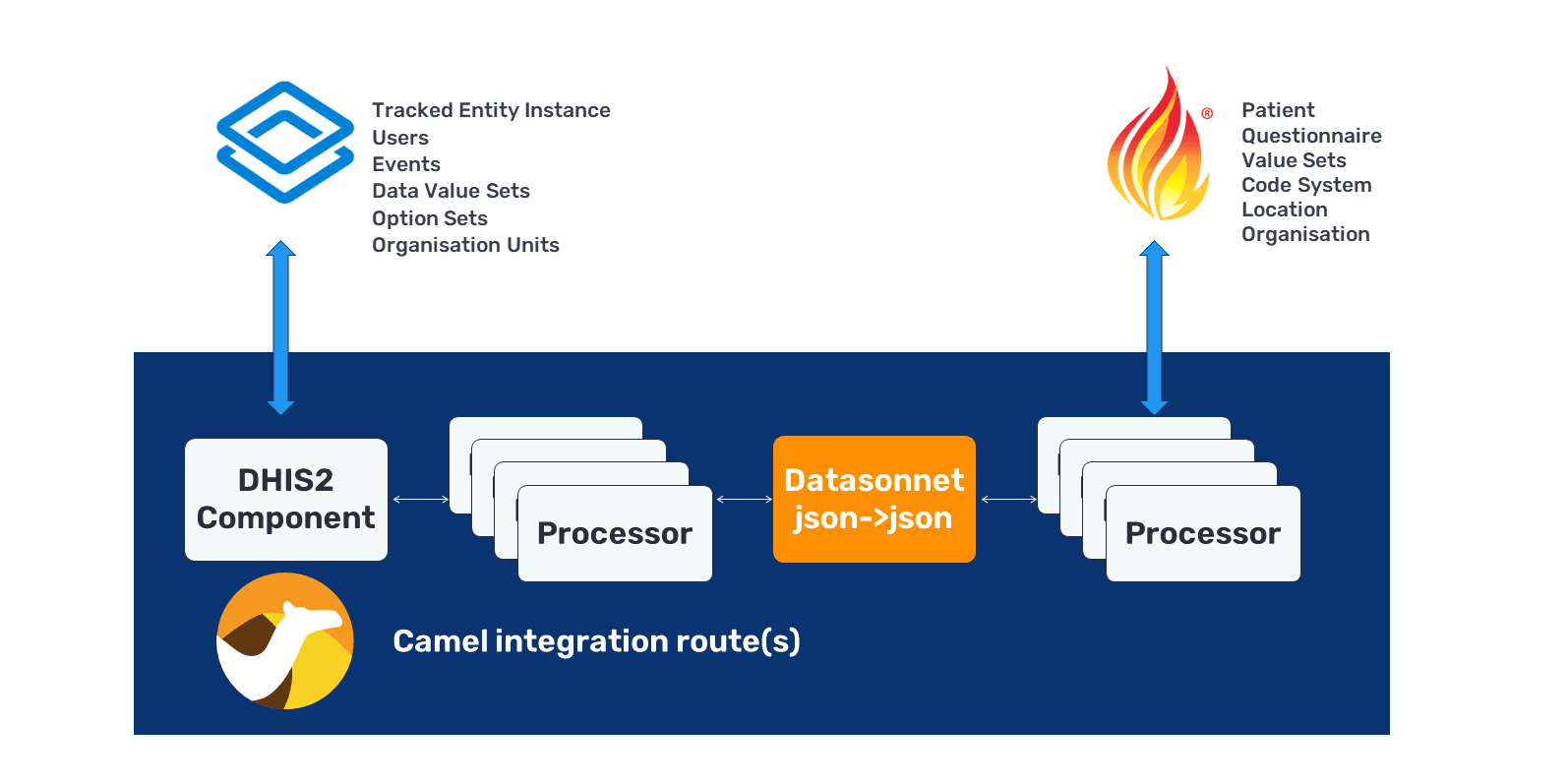
Un wrapper Apache Camel pour la bibliothèque client DHIS2 qui permet aux utilisateurs de l’utiliser dans les routes Camel (où les flux de travail d’intégration sont définis).
Montre comment les ressources DHIS2, telles que les unités d’organisation, peuvent être converties en bundles FHIR avant d’être téléchargées sur un serveur FHIR comme HAPI FHIR.
Montre comment les ressources DHIS2, telles que les unités d’organisation, peuvent être mappées à des bundles FHIR avec DataSonnet avant d’être téléchargées sur un serveur FHIR comme HAPI FHIR.
Dans les articles ci-dessous, vous pouvez lire comment les pays et les organisations utilisent et pilotent FHIR avec DHIS2 pour répondre aux besoins du monde réel.
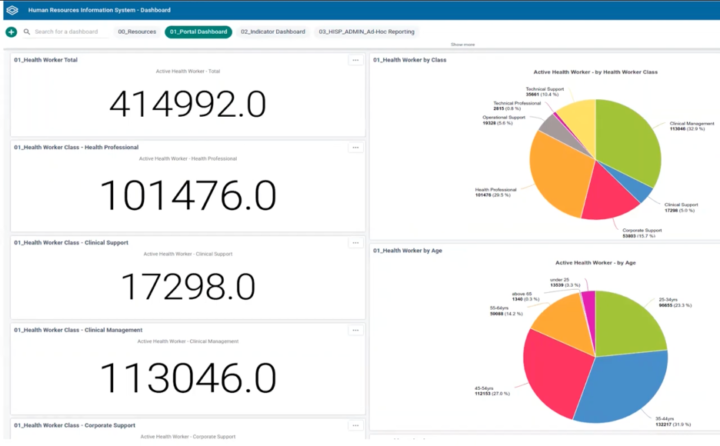
DHIS2 sert de plateforme pour étendre l’efficacité de l’entreposage et de l’analyse des données pour la planification des ressources humaines grâce à l’intégration et à l’interopérabilité.
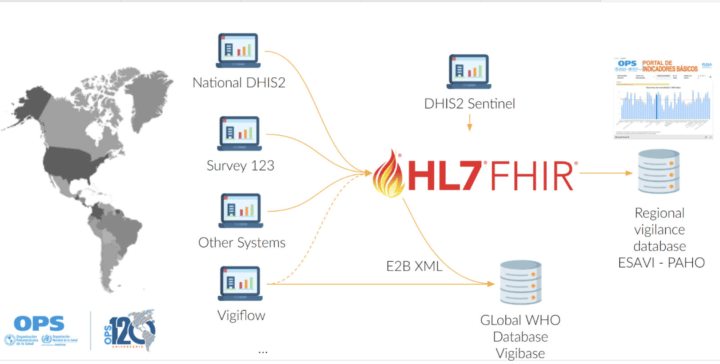
En soutenant l’introduction du vaccin COVID, l’Organisation panaméricaine de la santé s’est concentrée sur le renforcement de la pharmacovigilance après la vaccination, en tirant parti de l’interopérabilité basée sur FHIR.

Le Rwanda Biomedical Center, soutenu par les CDC américains, a démontré qu’un écosystème d’échange d’informations de santé basé sur des technologies open-source et des normes ouvertes peut soutenir la génération d’un ensemble complet de données pour le CBS VIH de routine.
L’équipe d’intégration de DHIS2 est très enthousiaste à l’idée de travailler avec les partenaires nationaux pour répondre aux besoins concrets de FHIR. Notre approche progressive de FHIR signifie que nous dépendons des cas d’utilisation du monde réel pour faire avancer le développement. Si vous avez un projet d’intégration FHIR spécifique lié à DHIS2, n’hésitez pas à nous contacter : integration@dhis2.org