DHIS2 Camel Component
An Apache Camel wrapper for the DHIS2 Client Library that allows users to use it in Camel routes (where integration workflows are defined).

DHIS2 supports the use of HL7 FHIR in health implementations. Metadata in DHIS2 systems can be mapped to standard FHIR profiles, providing compatibility with national FHIR patient profiles and WHO SMART guidelines. On this page, you can learn more about tooling and approaches for DHIS2 data exchange and integration using FHIR
HL7Ⓡ FHIRⓇ (Fast Healthcare Interoperability Resources) is a standard which is curated by Health Level Seven International. From the HL7 FHIR product description:
FHIR is an interoperability standard intended to facilitate the exchange of healthcare information between healthcare providers, patients, caregivers, payers, researchers, and any one else involved in the healthcare ecosystem. It consists of 2 main parts – a content model in the form of ‘resources’, and a specification for the exchange of these resources in the form of real-time RESTful interfaces as well as messaging and Documents.
Whereas previous standards like HL7 v2 have not disappeared, FHIR takes a modern approach, for example by making use of RESTful paradigms which are more familiar to modern web application developers. It has seen an increase in interest and uptake over the past few years, with major vendors such as Microsoft, Google, Epic, and others creating FHIR-enabled tooling and interfaces. There has also been considerable interest and work being done within the international development community, including the OpenHIE community as well as technical working groups within WHO.
FHIR defines a rich ontology of base resources such as Patient, Observation, ValueSet, CodeSystem, etc. The rapid evolution of FHIR has resulted in the need to establish different maturity levels for different resources. So whereas it is under fairly constant development, there are a growing subset of resources which have achieved normative status.
The base resources are defined with extensibility and customization in mind. The fields and codings required to describe a Patient in the United States for example, might differ substantially with those required in Norway or Sierra Leone. The process of customizing, extending and constraining base resources is known as profiling. Establishing consensus around profiles is a key activity in establishing actual interoperability between participating systems. In DHIS2 terms, this is similar to Tracked Entity Instances (TEIs) – the fact that two DHIS2 systems both support TEIs doesn’t necessarily imply they can exchange data without harmonizing attributes, option sets, etc.
The base FHIR resources are managed through the HL7 FHIR management group, but any organization can create and publish profiles. So for example, it is a common activity for national jurisdictions to create national profiles. There has been some attempt to harmonize these activities through efforts like the International Patient Summary.
A related concept to the FHIR profile is the FHIR Implementation Guide (IG). IG’s provide a consistent way of describing related collections of profiled FHIR resources to address particular problem domains. They typically incorporate machine readable artifacts as well as narrative text, examples, and so on.
DHIS2, like almost all large and established digital health software systems, is built around a data model which has evolved over many years to effectively meet a large range of use cases within the health domain and beyond. The model is stable, robust and well-documented. We see FHIR as an interoperability standard, rather than a replacement for our internal model. The challenge is thus to create effective mappings between resources within the DHIS2 model and equivalent or similar resources within the FHIR model. This challenge is not trivial, as both models are highly customizable and extensible. So we approach the problem incrementally and iteratively, preferring to ground our approach in concrete applications.
Technically this implies use of transformations, interfaces and facades, which translate FHIR resources onto the underlying DHIS2 data model using an integration framework such as Apache Camel (for example, transforming a Tracked Entity Instance (TEI) into a FHIR patient profile). This is described in greater detail in the technology section below.
This approach has already been used successfully in the real world. For example, as part of our work with PAHO’s regional vaccine safety (ESAVI) implementation, which uses a customized version of the DHIS2 AEFI Tracker metadata package to collect data which is mapped onto a FHIR profiled Questionnaire to facilitate data sharing with other systems, and which can subsequently support compatibility with the global Vigibase pharmacovigilance database. This is a good example of an interoperability process that is grounded in real-world needs in a specific country or regional context, as opposed to projects that are based on abstract blueprints, which tend to be more challenging and less impactful.
In all cases we have explored so far, we have been able to successfully transform DHIS2 data into FHIR. The DHIS2 integration team continues to work with local and global partners on specific FHIR needs and development of generic approaches that can be shared and adapted. If you have a problem that you need to solve with FHIR, get in touch with us: integration@dhis2.org
Mapping to Questionnaire / QuestionnaireResponse: FHIR Questionnaires provide a convenient mechanism for interoperability between systems which don’t necessarily share the same rich collection of domain specific FHIR resources. Native FHIR Repositories can map Questionnaires using, for example, SDC (Structured data Capture). Similarly on the DHIS2 side we can map Tracker and aggregate data entry forms to Questionnaires. The Questionnaire abstracts the difference in data model on both sides.
As discussed above, this approach has been used effectively with tracker data exchange by PAHO. We are also currently working on a standardized mapping between DHIS2 aggregate data sets and FHIR Questionnaires.
Mapping to Patient Resource: One specific FHIR profile that we have focused on is the International Patient Standard (IPS). The DHIS2 team has translated DHIS2 Tracker metadata to an IPS conformant Patient payload. This will eventually allow us to support the import and export of demographic data of patients (for example in referral of patients in the form of an international patient summary).
Exposing DHIS2 metadata as FHIR resources: We have developed transformations for expressing DHIS2 option sets and organisation units as FHIR ValueSets and mCSD compatible resources. Generalizing from this experience, we are working towards implementations being able to expose and describe their structural metadata more generally using FHIR.
Using the tools we have developed thus far, it is possible to take some aspects of the metadata from DHIS2 and produce a FHIR implementation guide from it. This means that countries and organizations that use DHIS2 as the national authoring environment (for collecting data on patients, aggregate reports, etc.) – which is a typical role for DHIS2 within a country’s digital health information architecture – can generate FHIR profiles that represent the information that is in their DHIS2 instance.
The DHIS2 integration team uses Apache Camel open-source middleware for a variety of integration projects. To make life easier for integration engineers we have developed a DHIS2 java client library and a DHIS2 Camel component, which makes it easy to create routes between DHIS2 endpoints and other Camel components (such as FHIR, HL7v2x, etc.). We have found it particularly useful for supporting FHIR data formats and transformations. There are other middleware options that exist, but we have selected Apache Camel due to its flexibility, maturity and extensive use in a variety of industries, which means that many connectors already exist for it that can help link DHIS2 to whatever system countries want to integrate it with. There are several examples of similar uses of Camel for transforming health data, including the OpenMRS ETL tool, the OpenEHR FHIR bridge and the Open eHealth Integration Platform.
This approach works by communicating with the DHIS2 instance on one side of the Apache Camel connector, then performing a transformation that translates the DHIS2 data into FHIR format. There are two methods for doing this:
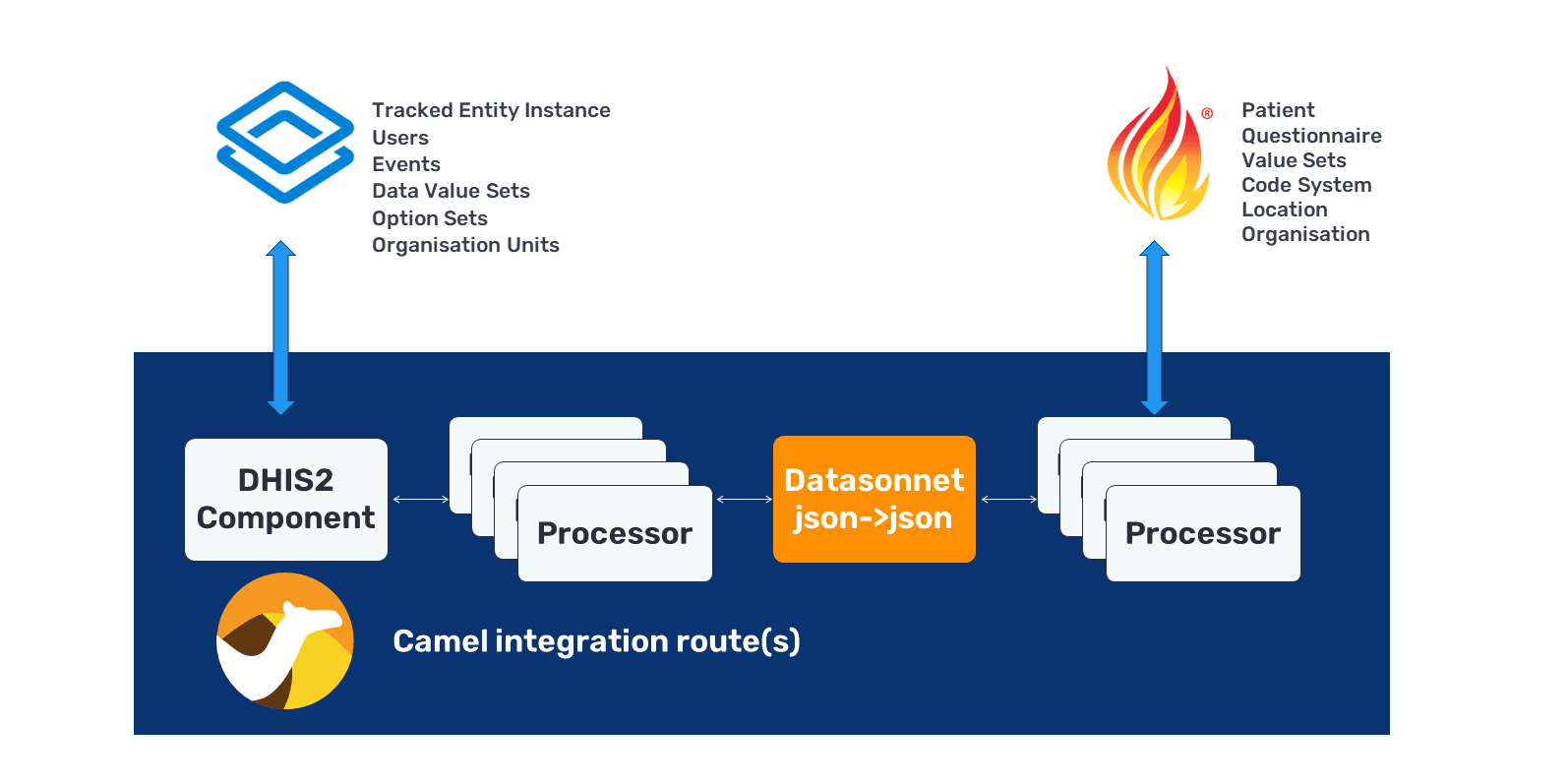
An Apache Camel wrapper for the DHIS2 Client Library that allows users to use it in Camel routes (where integration workflows are defined).
Shows how DHIS2 resources, such as organisation units, can be converted to FHIR bundles before being uploaded to a FHIR server like HAPI FHIR.
Shows how DHIS2 resources, such as organisation units, can be mapped to FHIR bundles with DataSonnet before being uploaded to a FHIR server like HAPI FHIR.
In the articles below, you can read about how countries and organizations are using and piloting FHIR with DHIS2 to address real-world needs.
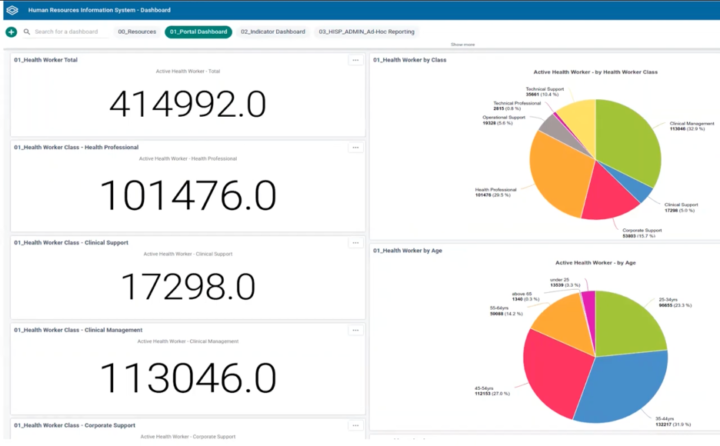
DHIS2 serves as a platform to extend effective data warehousing and analysis for human resource planning through integration and interoperability.
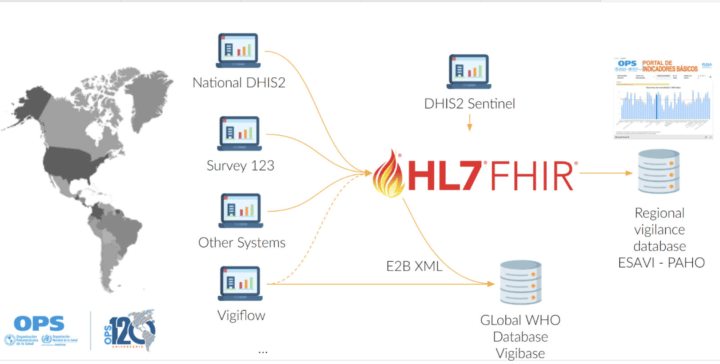
Supporting the introduction of the COVID vaccine, the Pan American Health Organization focused on strengthening pharmacovigilance following immunization, leveraging FHIR-based interoperability.

The Rwanda Biomedical Center, supported by the US CDC, demonstrated that a health information exchange ecosystem based on open-source technologies and open standards can support the generation of a complete dataset for routine HIV CBS.
The DHIS2 integration team is excited to work with country partners to address concrete FHIR needs. Our incremental approach to FHIR means that we are dependent on real-world use cases to drive the development forward. If you have a specific FHIR integration project related to DHIS2, please get in touch with us: integration@dhis2.org